Zecheng (Justin) LiI am graduated from Carnegie Mellon University and UCSD, specializing in Machine Learning, multimodal, agentic system, RAG, and deep recommender systems. Currently, I'm working at TikTok as a Machine Learning Engineer dedicated to personalized search engine development, building both C++ infrastructure and search recommendation deep models. Previously, I've been a Machine Learning Engineer and early founder at Metaverse Museum, a Research Intern at Argonne National Laboratory developing AutonomieAI, and a Project Manager & developer at Equiem leading an enterprise-level RAG pipeline development. I have also been a Graduate Research Assistant at CMU TEEL Lab helping develop AI coursework and software for online studies. In my undergrad, I was a research assistant at the Power Transformation Lab and served as a Teaching Assistant for (Cogs 118b), an advanced unsupervised machine learning course at UCSD. My research interests include multimodal AI, reasoning, agentic systems, and reinforcement learning. My key projects include an agentic RAG-based LLM Chatbot using knowledge graph (Neo4j, LangGraph) and an advanced image editing toolkit using LLM, LMM, and VLM technologies. Proficient in Python, TensorFlow, PyTorch, Java, and experienced with GCP, AWS and Docker, I'm passionate about pushing the boundaries of AI applications in real-world scenarios. |

|
ProjectsSome are not listed and are still being processed. |
|
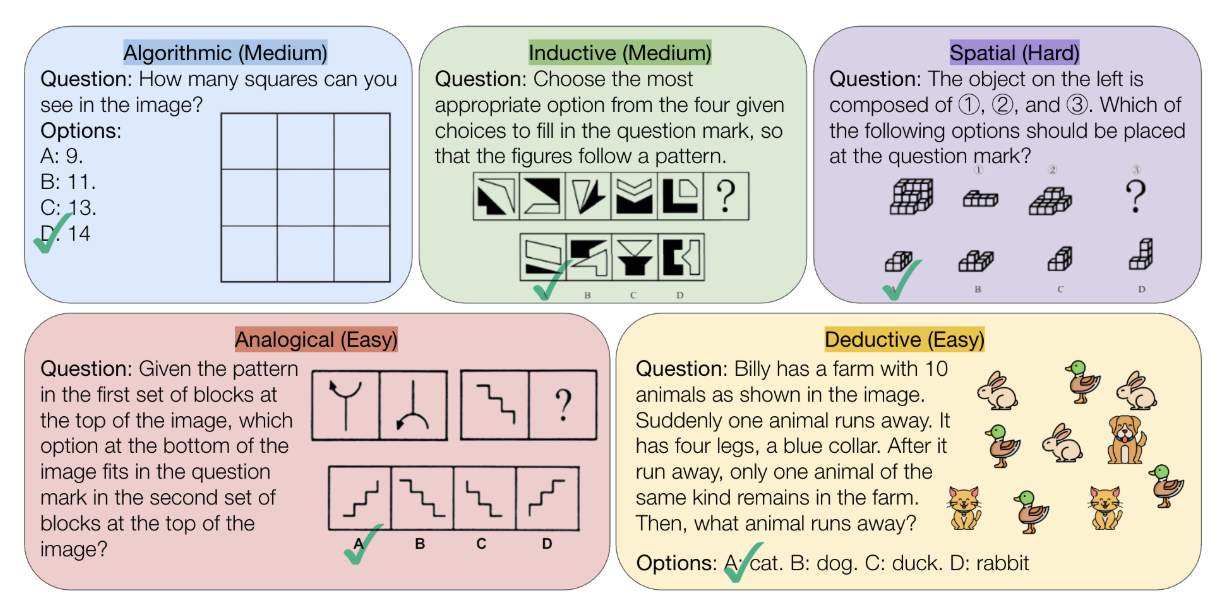
VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain KnowledgeYueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, Xiang Yue VisualPuzzles: a benchmark that targets visual reasoning while deliberately minimizing reliance on specialized knowledge. One major source of our questions is manually translated logical reasoning questions from the Chinese Civil Service Examination., 2025 website / preprint / code VisualPuzzles consists of 1168 diverse questions spanning five categories: algorithmic, analogical, deductive, inductive, and spatial reasoning. Each puzzle is labeled as easy, medium, or hard. While there has been significant progress in curating high-quality text-only logical reasoning benchmarks, there remains a notable gap in the development of comprehensive multimodal logical reasoning benchmarks. Existing multimodal benchmarks tend to focus heavily on knowledge-based tasks, which are biased towards models pre-trained on extensive knowledge bases, making them less accessible to smaller models with limited pretraining on knowledge bases. Moreover, these benchmarks often concentrate on a single type of logical reasoning, lacking the breadth necessary to fully evaluate a model’s reasoning capabilities across diverse scenarios. This narrow focus limits their utility in assessing general logical reasoning skills in multimodal contexts, underscoring the need for more balanced, diverse, and inclusive multimodal benchmarks. |
|
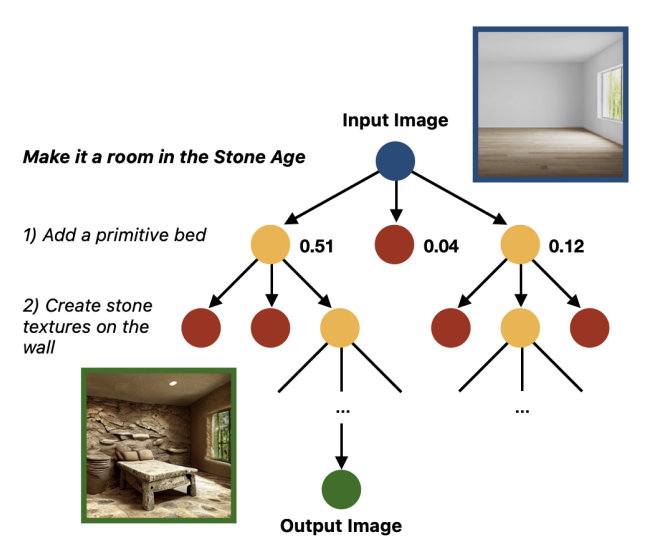
AutoEdit: Breaking Down Complex Instructions for Improved Image Editing Using DiffusionSudeep Agarwal, Zecheng Li, Victor Deng A Tree of Thoughts Heuristic Search Algorithm for Multimodal Models, 2024 preprint Recent work has shown impressive results for editing images with human instructions using diffusion models. Large multimodal models have demonstrated strong image understanding for a wide variety of domains, while language models have become more capable at reasoning, planning. and problem solving for complex tasks. However, current image editing methods still struggle with complex edits that are vague or require multiple steps. To address these challenges, we introduce AuTOEDIT, an agent that is able to use its understanding of an image to break down complex edits into simple ones to produce high quality results that maintain alignment with human intent. We demonstrate strong results that show that our method outperforms (by 17% to 43%) current editing methods for complex edits. |

|
HalluPAQ: Efficient Confidence Scoring for Hallucination Detection in Domain-Specific LLMsTianze Shou, Jing Zhang, Zecheng Li Probable Asked Questions (PAQ) for Assessing the Credibility of LLM Outputs, 2024 preprint / code Large Language Models (LLMs) demonstrate immense potential but are often compromised by “hallucinations”-plausible yet factually incorrect outputs. To address this, we introduce HalluPAQ, a novel, cost-effective method that enhances the reliability of LLMs by assessing the credibility of their outputs. Utilizing a vector database, HalluPAQ indexes and queries a corpus of Probable Asked Questions (PAQ), efficiently determining the veracity of LLM responses by measuring their similarity to known knowledge. This system not only provides rapid evaluations with an average overhead time of 0.00455 seconds but also outperforms existing methods like SelfCheckGPTNLI and FactScore in ROC-AUC scores, proving its effectiveness in detecting and warning against hallucinations. HALLUPAQ’s approach sets a new standard for safe LLM deployment, paving the way for future advancements in maintaining the trustworthiness of model-generated content. |

|
Innovative Automatic Speech Recognition with Transformer ArchitectureZecheng (Justin) Li Advanced ASR System Using Pyramid Bi-LSTM and Transformer Models, 2023 In this project, we delve into the realm of Automatic Speech Recognition (ASR) by employing an advanced architecture that synergizes Pyramid Bi-LSTM with Transformer models. This combination is a leap forward in efficiently processing and encoding audio data. Our system is designed to address the challenges of traditional ASR systems by introducing custom modules developed in PyTorch, such as pBLSTM for effective dimensionality reduction in time and LockedDropout for enhancing model regularization. |

|
Pre-trained BERT Text Classification Application with Amazon-Massive-Intent DatasetWenqian, Keyu, Xiaotong, Yunze, Zecheng Li Encoder-Decoder Neural Network with pre-trained BERT, 2022 report / code This project is about using a type of artificial intelligence called BERT to understand what people are trying to say. Specifically, the project focuses on classifying different types of text based on their meaning or intent. For example, if someone types “I want to order a pizza,” the BERT model will recognize that the intent is to order food. The model uses pre-existing knowledge to do this, which has been gained through being trained on a large amount of data beforehand. |
|
COCO-2015 Image Caption Generation Using Encoder-Decoder Neural Network Architecture with CNN and LSTMZecheng Li, Wenqian Zhao, Lainey Liu, Mingkun Sun Encoder-Decoder Neural Network Project of CSE151B, 2022 report / code This project focus on constructing an encoder-decoder neural network architecture that generates captions for the given image. |

|
Long-Term Wind Forecasting Using Machine LearningZecheng Li Personal Project of MAE 207 Graduate Class: Topics in Renewable Energy Integration, 2022 preprint / slides / code This work can be used to predict long-term wind generation nationwide, providing convenience to dispatchers and policy makers who can predict uncertainties in advance and plan accordingly. |

|
Applying Supervised and Unsupervised Learning in Fraud DetectionZecheng Li, Lechuan Wang, Yifan Lin, Zhenyi Chen, Qianxi Gong, Yicheng Qu Project of Cogs118b: Introduction to Unsupervised Learning, 2022 slides / code This work can be used to examine the difference in performance between supervised and unsupervised learning for fraud detection. We also applied PCA on the dataset to see if the performance remains robust after applying PCA to reduce the computational burden. |

|
Relationship between Obesity Rate and living standardsZhuoran Li, Zhaoyi Yu, Zecheng Li, Gao Mo Project of COGS 108: Data Science in Practice, 2022 report / code Our research on obesity and living conditions is generally a quite common topic for those interested in the subject. With our findings, we can share with the community our findings of which aspects in the living standards contributed most to the cause or the correlation to the obesity rate on a macro level. This would benefit studies that focus on obesity or health in general, and it can also help the government to advocate policy that aims to reduce the obesity rate and promote healthy living. |
|
Design and source code from Jon Barron's website. Forked from the Jekyll varient by Leonid Keselman. |